Evolving Interpretable Visual Classifiers with Large Language Models
draw_abstract
Abstract
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce LLM-Mutate, an evolutionary search algorithm that utilizes a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
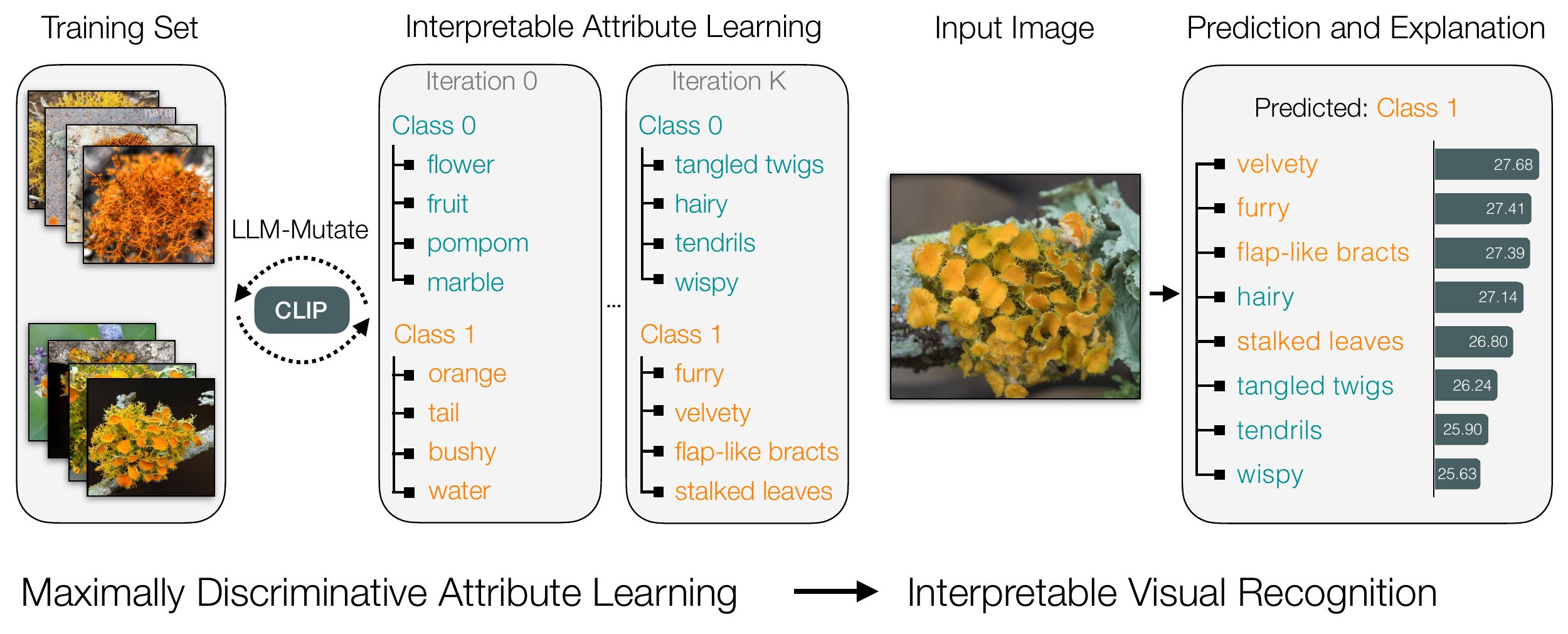
Method Overview
LLM-Mutate is an evolutionary algorithm that learns sets of discrete language attributes per class. The mutation and cross-over operations, which are mechanisms to introduce new parameter hypotheses, are replaced by a large language model that uses in-context learning over past attributes and their scores to iteratively generate better attributes.
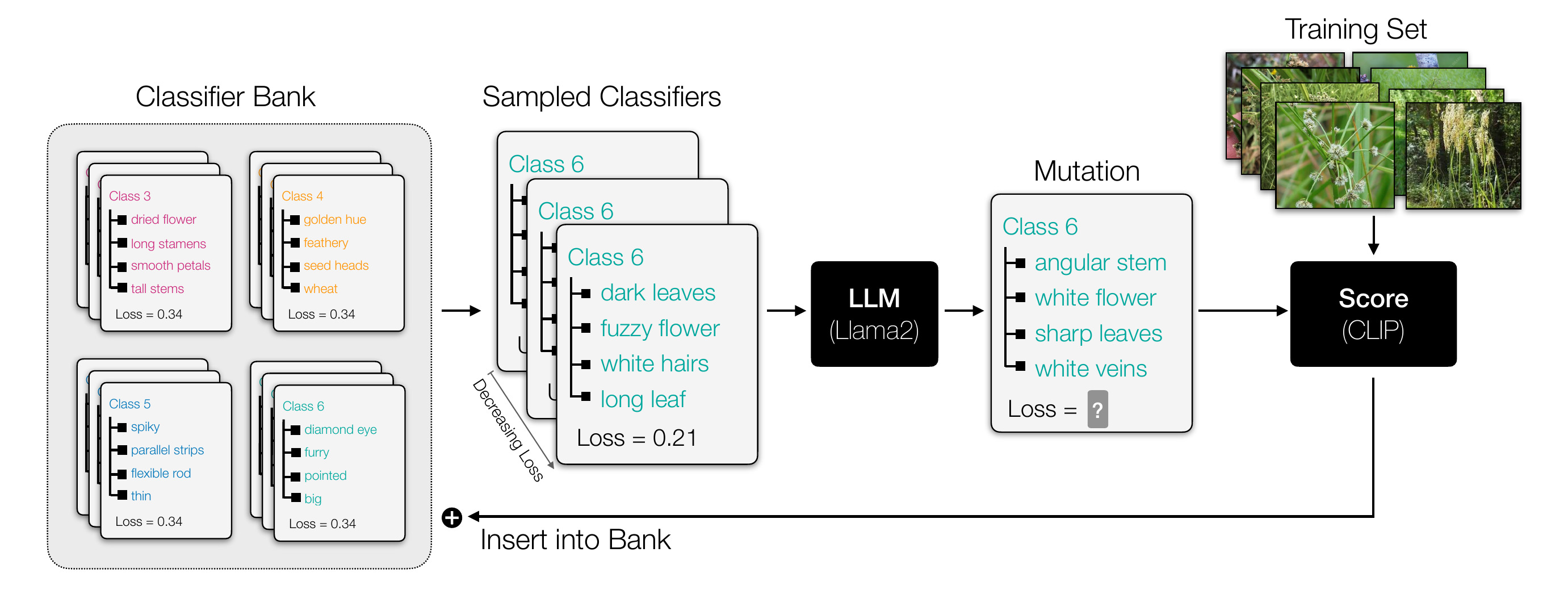
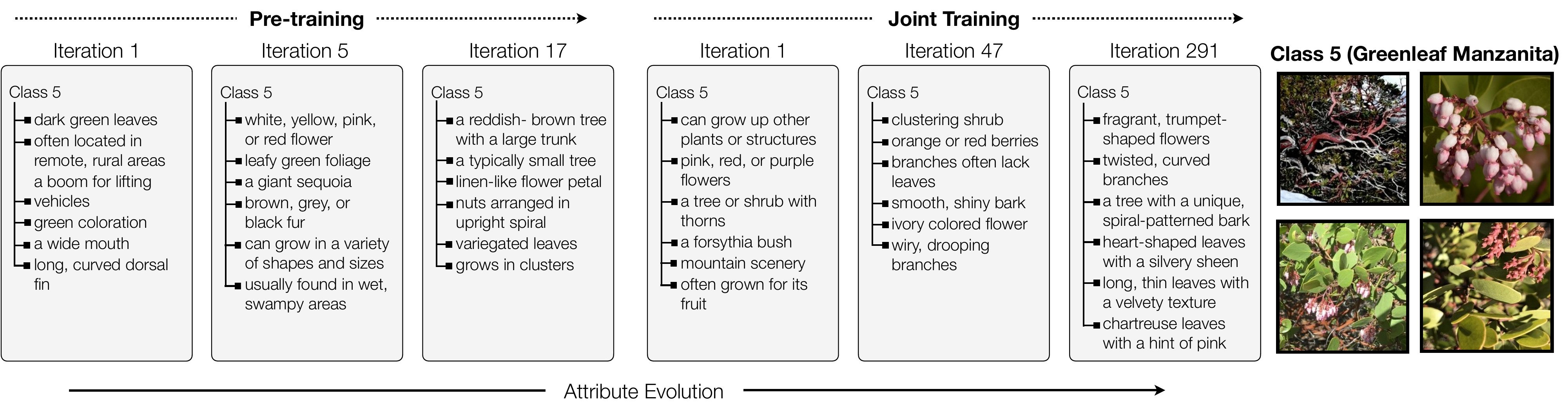
Our method starts with a random set of attribute for each class. As the training progresses the attributes evolve to be more specific to the class while being interpretable.
Results
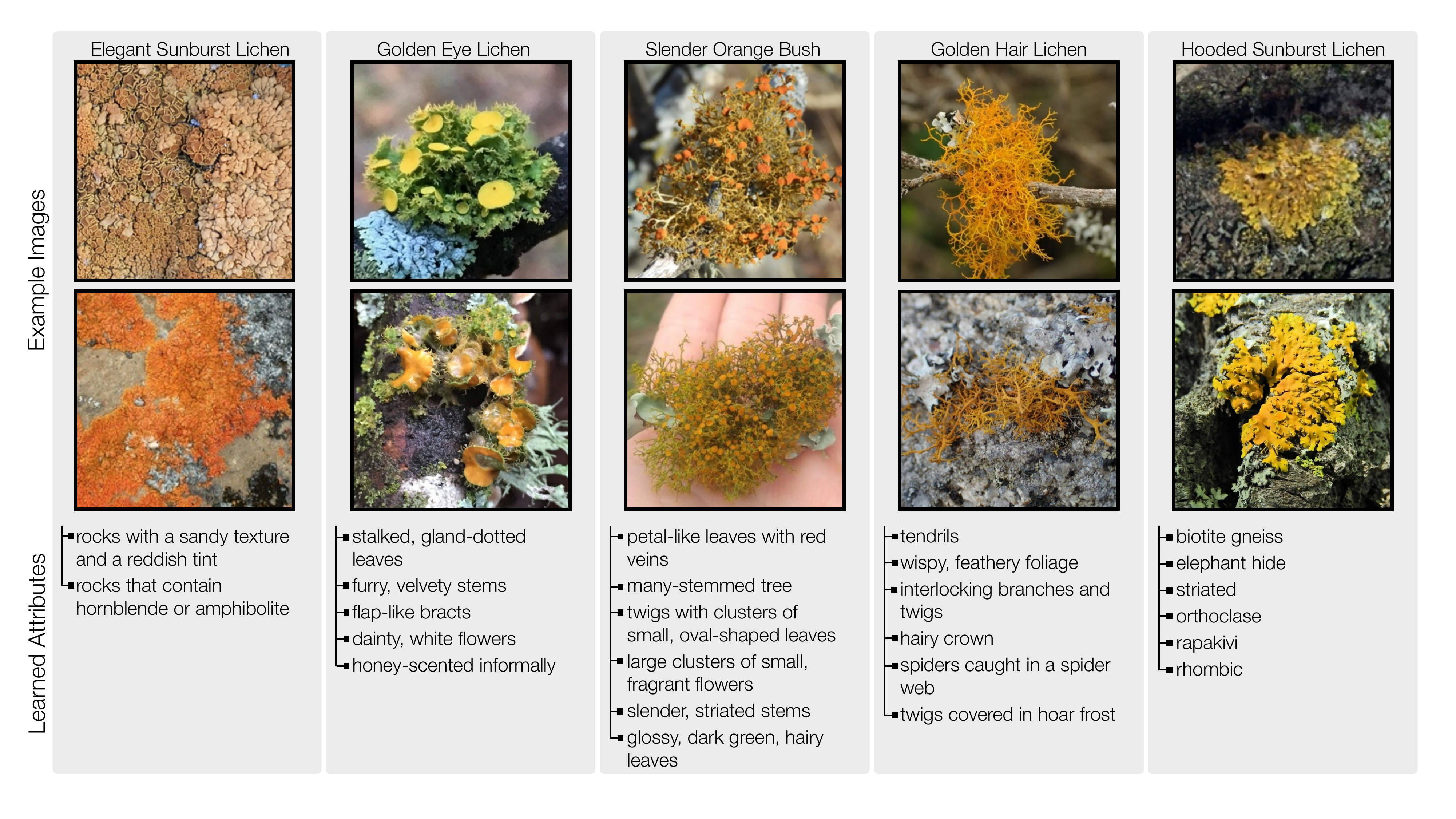
Discovering attributes for rare concepts
Our method can discover attributes for specialized images that have been infrequently discussed on the internet due to the nature of their specificity, such as species of Lichen from the iNaturalist dataset.
Discovering attributes for novel concepts
Our method can also discover attributes for completely novel concepts that do not appear on the internet and to which language models lack familiarity. We show that our method can discover attributes for such novel concepts such as Kiki and Bouba categories.

Quantitative comparison to other methods
We evaluate our method on five rare iNaturalist families and two sets Kiki-Bouba like novel concepts. Our method outperforms all the baselines with language bottleneck and results in more interpretable attributes.
| iNaturalist | Kiki-Bouba | ||||||
|---|---|---|---|---|---|---|---|
| Lichen | Wrasse | Wild Rye | Manzanita | Bulrush | KB1 | KB2 | |
| Method | 28.3 | 16.0 | 22.0 | 18.0 | 24.0 | 20.6 | 19.2 |
| Class Name | 23.3 | 32.0 | 32.0 | 26.0 | 26.0 | 38.7 | 38.8 |
| Classification by Description [1] | 30.0 | 34.0 | 36.0 | 28.0 | 20.0 | 28.8 | 36.8 |
| Gradient-based Approach | 23.3 | 20.0 | 40.0 | 20.0 | 20.0 | 16.7 | 55.6 |
| Ours | 48.3 | 44.0 | 58.0 | 58.0 | 42.0 | 79.2 | 59.4 |
Since our method is trained discover attributes that are discriminative, the margin (confidence) of classification is also higher compared to other methods.
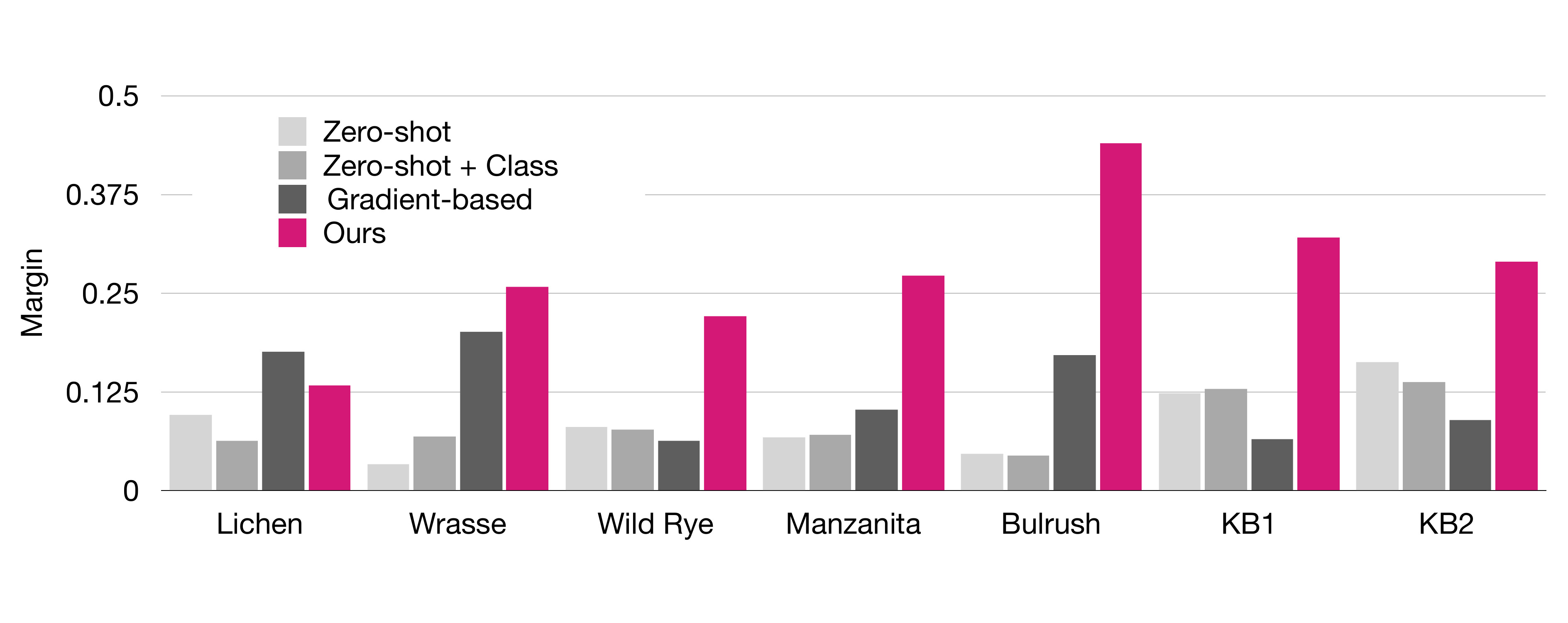
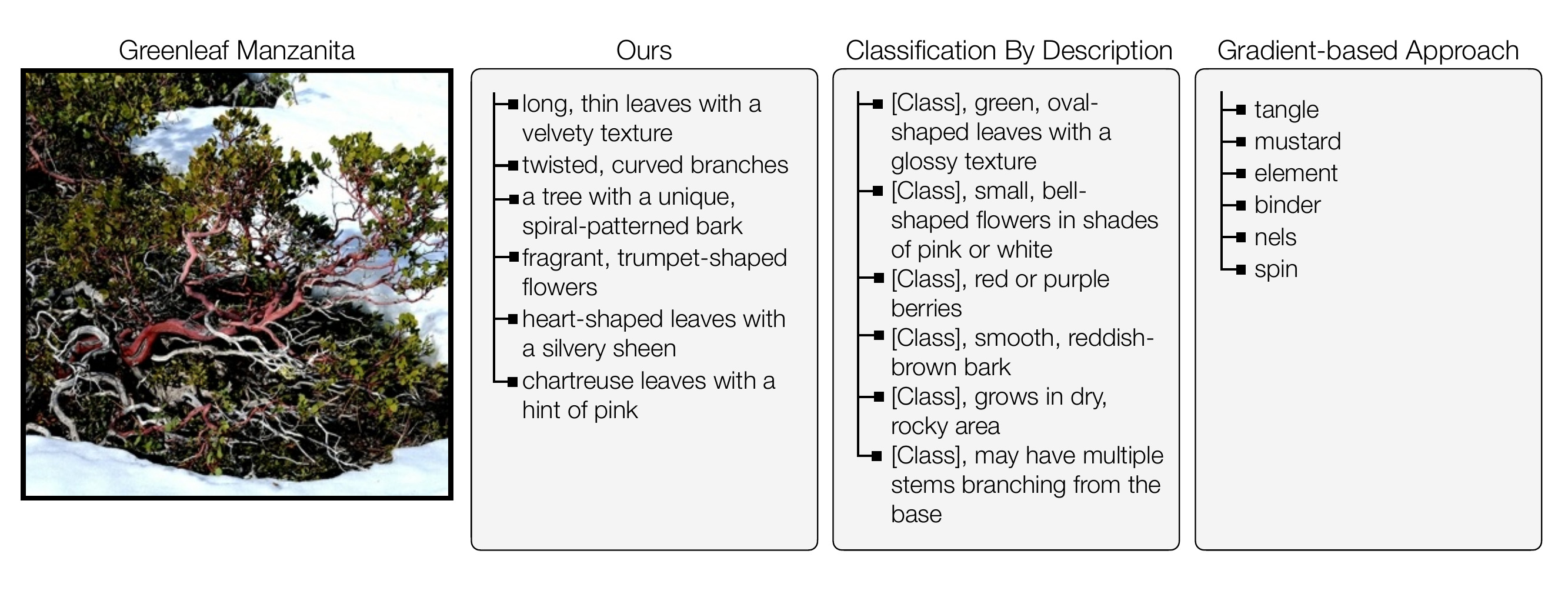
Qualitative comparison to other methods
The learned attributes are more detailed and discriminative of the species within the family, compared to the classification by description (CBD) baseline. Furthermore, our method's class probability distributions tend to be more concentrated than CBD's.
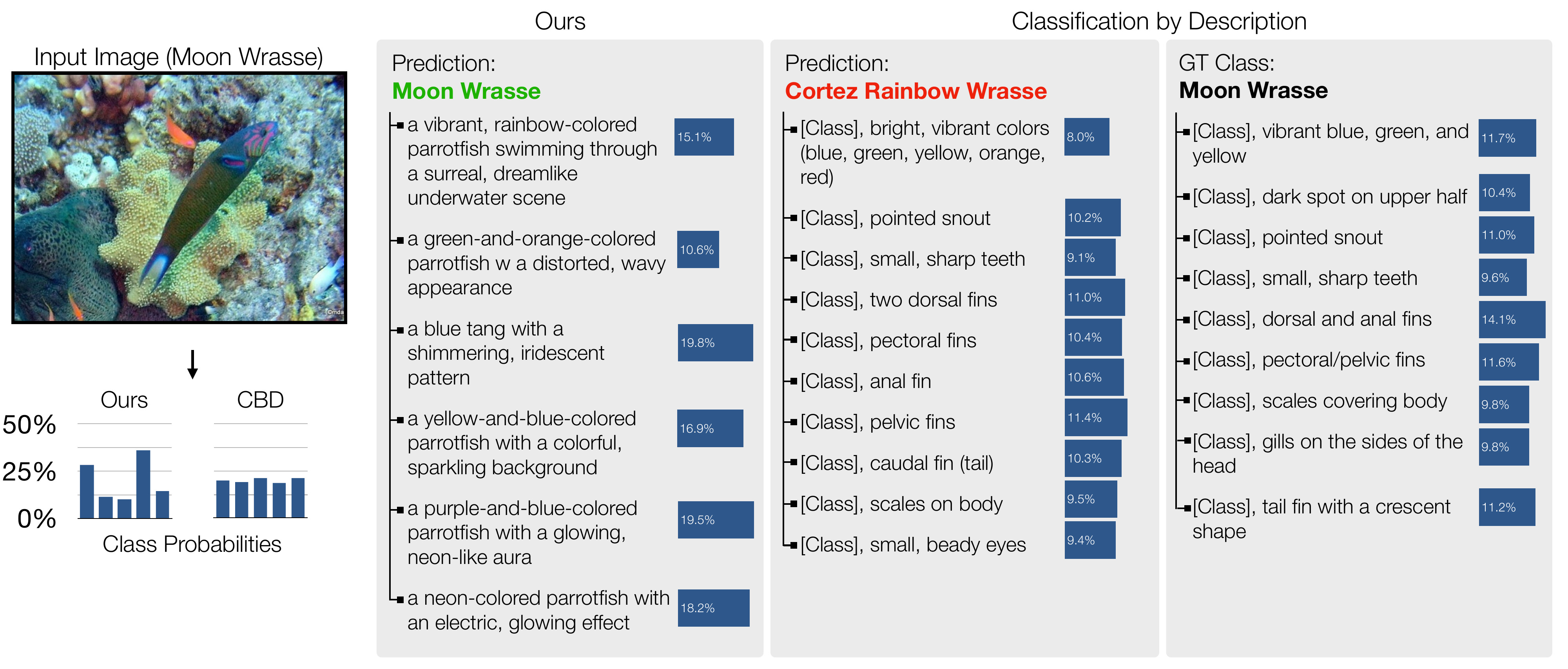
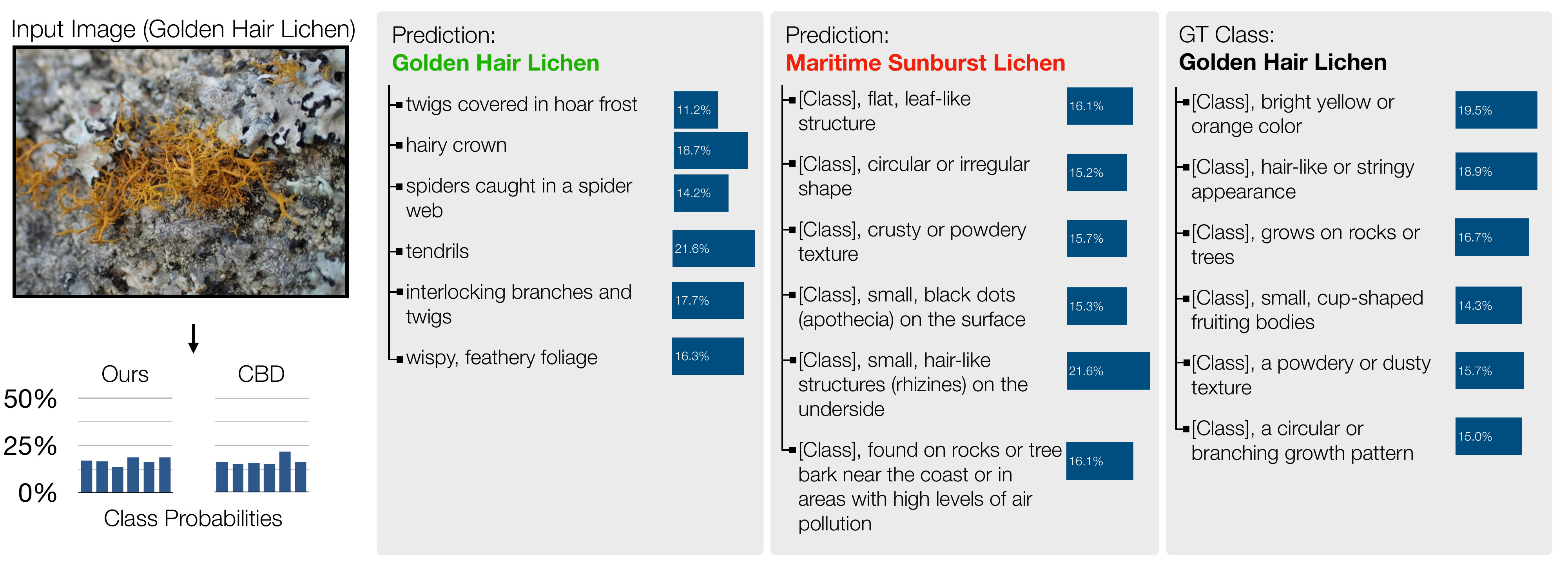

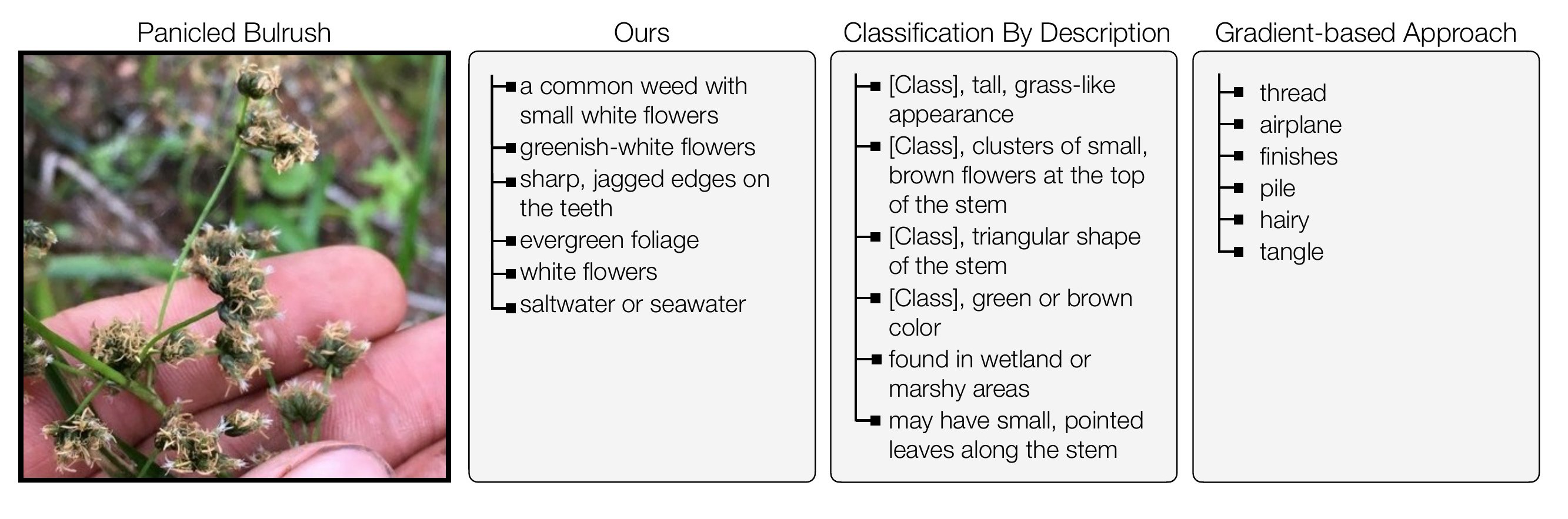
Our method can discover attibutes that are discriminative while being interpretable. CBD often produces reasonable attributes, but they are not discriminative, resulting in poor recognition accuracy. Gradient-based methods often produce poor attributes due to optimization difficulties.

Discovering biases in datasets
By having explicitly interpretable attributes as the bottleneck for classification, we can directly observe whether the classifier is picking up on dataset bias to perform prediction. The squirreltail species is the only species that commonly lives in drought habitats amongst the family, and the learned attributes are names of plants that live in the desert. The ability to explicitly audit bias is an advantage of our interpretable method.

format_quote Citation
@article{llmmutate-24,
title={Evolving Interpretable Visual Classifiers with Large Language Models},
author={Chiquier, Mia and Mall, Utkarsh and Vondrick, Carl},
booktitle={CoRR},
year={2024}
}
Acknowledgements
We are grateful to the Computer Vision Lab at Columbia University for their useful feedback.
This webpage template was inspired by this project page.